

Stream Processing
Stream processing is a data processing technique that involves ingesting a continuous stream of data and performing computations on the data in real time. It is used for processing scenarios that have very short latency requirements, typically measured in seconds or milliseconds. Data that is ready for analysis is either sent directly to a dashboard or loaded into a persistent data store such as ADLS or Azure Synapse Analytics dedicated SQL pool for long-term analysis. Some examples of stream processing are listed here:
- Analyzing click-stream data to make recommendations in real-time
- Observing biometric data with fitness trackers and other IoT devices
- Monitoring offshore drilling equipment to detect any anomalies that indicate it needs to be repaired or replaced
Cloud-based stream processing workflows generally use the following components:
- Real-time message ingestion—This component captures data as messages in real time from different technologies that generate data streams. Azure Event Hubs and Azure IoT Hub are two PaaS offerings that data architects can use for real-time message ingestion. Several organizations leverage Apache Kafka, a popular open-source message ingestion platform, to process data streams. Organizations can move their existing Kafka workloads to Azure with the Azure HDInsight Kafka cluster type or the Azure Events for Kafka protocol.
- Stream processing—This component transforms, aggregates, and prepares data streams for analysis. These technologies can also load data in persistent data stores for long-term analysis. Azure Stream Analytics and Azure Functions are two PaaS offerings that data engineers can use to receive data from a real-time ingestion services and apply computations on the data.
- Apache Spark—This is a popular open-source data engineering platform that supports batch and stream processing. Stream processing is performed with the Spark structured streaming service, a processing service that transforms data streams as micro-batches in real time. Spark structured streaming jobs can be developed with Azure Databricks, the Azure HDInsight Spark cluster type, or an Azure Synapse Analytics Apache Spark pool. The collaborative nature and ease of use with Azure Databricks makes it the preferred service for Spark structured streaming jobs.
- Object storage—Data streams can be loaded into object storage to be archived or combined with other datasets for batch processing. Stream processing services can use an object store such as ADLS or Azure Blob Storage as a destination, or sink, data store for processed data. Some real-time ingestion services such as Azure Event Hubs can load data directly into object storage without the help of a stream processing service. This is useful for organizations that need to store the raw data streams for long-term analysis.
- Analytical data store—This is a storage service that serves processed data streams to analytical applications. Azure Synapse Analytics, Azure Cosmos DB, and Azure Data Explorer are services in Azure that can be used as an analytical data store for data streams.
- Analysis and reporting tools—Processed data can be written directly to a reporting tool such as a Power BI dashboard for instant analysis.
As discussed in Chapter 1, stream processing workflows can use one of two approaches: live or on demand. The “live” approach is the most commonly used pattern, processing data continuously as it is generated. The “on-demand” approach persists incoming data in object storage and processes it in micro-batches. An example of this approach is illustrated in Figure 5.2.
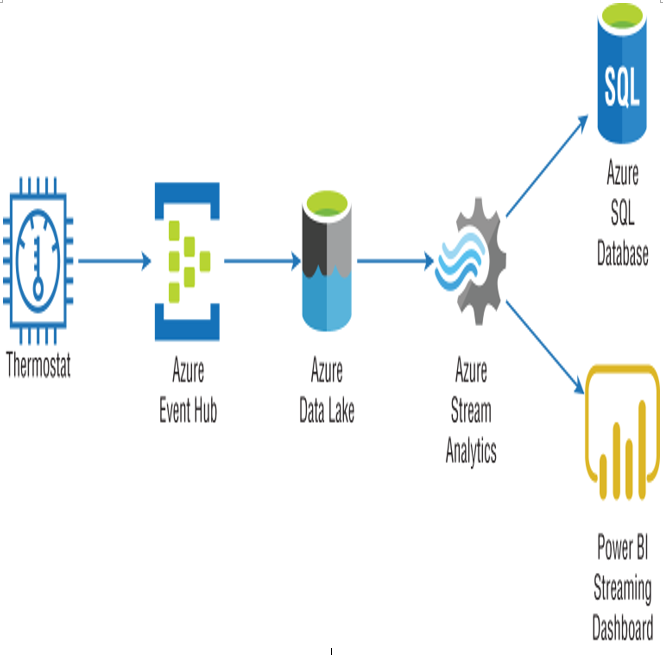
FIGURE 5.2 On-demand stream processing example
Leave a Reply