
Dedicated SQL Pools
Azure Synapse Analytics dedicated SQL pools (formerly Azure SQL Data Warehouse) are relational data stores that use a massively parallel processing (MPP) architecture to optimally manage large datasets. This can be done by separating compute and storage by using a SQL engine to perform computations and Azure Storage to store the data. Dedicated SQL pools use a relational schema, typically a star schema, to serve data to users as tables or views for business intelligence applications.
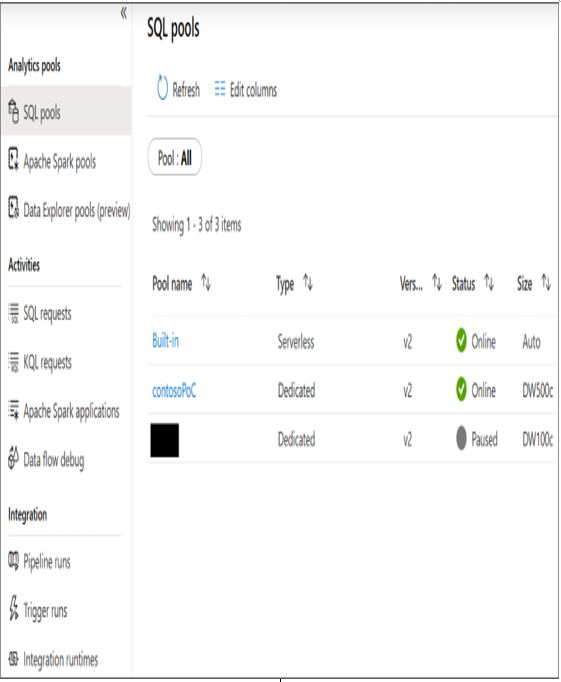
FIGURE 5.42 Synapse Studio Monitor page
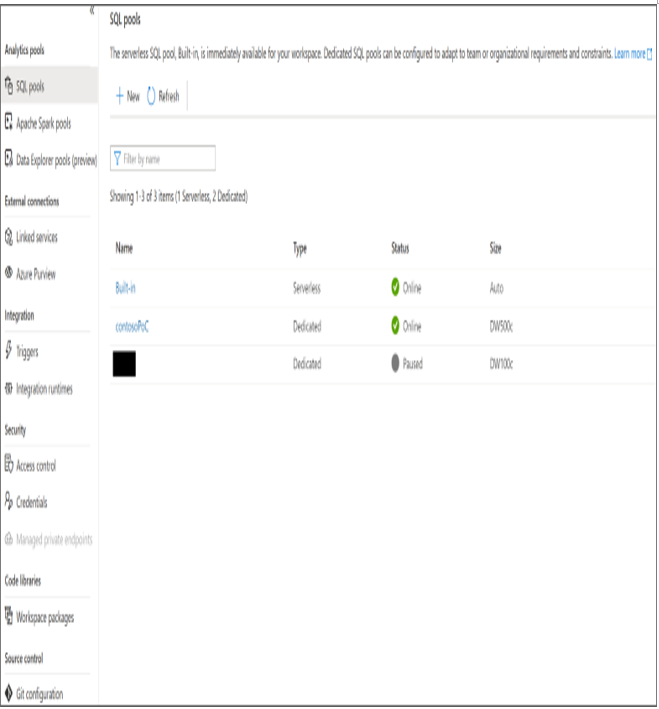
FIGURE 5.43 Synapse Studio Manage page
In a modern data warehouse architecture, a dedicated SQL pool is at the end of an ETL/ELT process, serving as the single source of truth for data analysts and BI applications. Tables using columnstore compression can store an unlimited amount of data, making dedicated SQL pools the ideal destination data store for big data workloads that process several terabytes or even petabytes worth of data. Additional processes can also extract subsets of data that represent specific business segments from a dedicated SQL pool and load them into Azure Analysis Services or Power BI OLAP models for self-service BI scenarios.
As mentioned in Chapter 2, dedicated SQL pools shard data into 60 distributions across one or more compute nodes depending on the dedicated SQL pool’s service level objective (SLO). Tables can be defined with one of three distribution patterns to optimize how data is sharded throughout the distributions. The following list is a quick reminder of the three distribution patterns and when to use each one:
- Hash distribution uses a hash function to deterministically assign each row to a distribution. When defining a table with this distribution type, one of the columns is designated as the distribution column. This distribution type offers the most optimal query performance for joins and aggregations on large tables. For this reason, large fact tables are typically defined as hash distributed tables. However, keep in mind that the values of a column designated as the distribution column cannot be updated. The column must also have a high number of unique values and a low number of null values. Poorly chosen distribution columns can lead to unacceptable query response times that cannot be resolved without re-creating the table. Use round robin distribution instead of hash distribution if there are no suitable distribution columns for a large fact table.
- Round robin distribution evenly and randomly distributes rows across all 60 distributions. Staging tables and fact tables without a good distribution column candidate are typically defined as round robin tables.
- Replicated tables cache a full copy of a table on the first distribution of each compute node. This removes the need to shuffle data when querying data from multiple distributions. However, replicated tables can require extra storage, making them impractical for large tables or tables that are frequently written to. For this reason, only small tables (less than 2 GB) or tables that store static data (such as reference data) are defined as replicated tables.
Leave a Reply