

Data Processing Techniques
Batch and stream processing are two data processing techniques that are used to manipulate data at rest and in real time. As discussed in Chapter 1, these techniques can be leveraged together in modern data processing architectures such as the Lambda architecture. This empowers organizations to make decisions with a wide variety of data that is generated at different speeds. Let’s examine each of these techniques further in the following sections before exploring how they can be used in the same solution.
Batch Processing
Batch processing activities act on groups, or batches, of data at predetermined periods of time or after a specified event. One example of batch processing is a retail company processing daily sales every night and loading the transformed data into a data warehouse. The following list included reasons for why you would want to use batch processing:
- Working with large volumes of data that require a significant amount of compute power and time to process
- Running data processing activities during off-hours to avoid inaccurate reporting
- Processing data every time a specific event occurs, such as a blob being uploaded to Azure Blob storage
- Transforming batches of semi-structured data, such as JSON or XML, into a structured format that can be loaded into a data warehouse
- Processing data that is related to business intervals, such as yearly/quarterly/monthly/weekly aggregations
Data architects can implement batch processing activities using one of two techniques: extract, transform, and load (ETL) or extract, load, and transform (ELT). ETL pipelines extract data from one or more source systems, transform the data to meet user specifications, and then load the data in an analytical data store. ELT processes flip the transform and load stages and allow data engineers to transform data in the analytical data store. Because the ELT pattern is optimized for big data workloads, the analytical data store must be capable of working on data at scale. For this reason, ELT pipelines commonly use MPP technologies like Azure Synapse Analytics as the analytical data store.
Batch processing workflows in the cloud generally use the following components:
- Orchestration engine—This component manages the flow of a data pipeline. It handles when and how a pipeline starts, extracting data from source systems and landing it in data lake storage, and executing transformation activities. Developers can also leverage error handling logic in the orchestration engine to control how pipeline activity errors are managed. Depending on the design, orchestration engines can also be used to move transformed data into an analytical data store. Azure Data Factory (ADF) is a common service used for this workflow component.
- Object storage—This is a distributed data store, or data lake, that hosts large amounts of files in various formats. Developers can use data lakes to manage their data in multiple stages. This can include a bronze layer for raw data extracted directly from the source, a silver layer that represents the data after being scrubbed of any data quality issues, and a gold layer that stores an aggregated version of the data that has been enriched with domain-specific business rules. ADLS or Azure Blob Storage can be used for this workflow component.
- Transformation activities—This is a computational service that is able to process long-running batch jobs to filter, aggregate, normalize, and prepare data for analysis. These activities read source data from data lake storage, process it, and write the output back to data lake storage or an analytical data store. Azure Databricks, Azure HDInsight, Azure Synapse Analytics, and ADF mapping data flows are just a few examples of compute services that can transform data.
- Analytical data store—This is a storage service that is optimized to serve data to analytical tools such as Power BI. Azure services that can be used as an analytical data store include Azure Synapse Analytics and Azure SQL Database.
- Analysis and reporting—Reporting tools and analytical applications are used to create infographics with the processed data. Power BI is one example of a reporting tool used in a batch processing workflow.
Figure 5.1 illustrates an example of a batch processing workflow that uses ADF to extract data from a few source systems, lands the raw data in ADLS, processes the data with a combination of Azure Databricks and ADF mapping data flows, and finally loads the processed data into an Azure Synapse Analytics dedicated SQL pool.
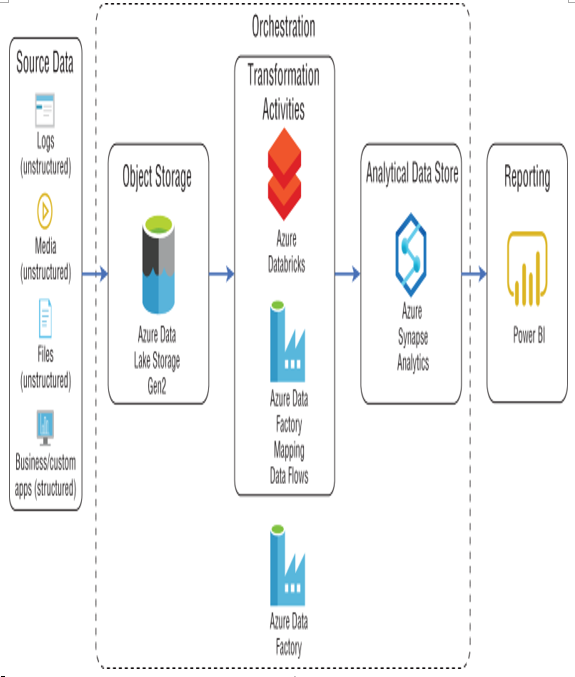
FIGURE 5.1 Batch processing example
Leave a Reply